

The gap I keep seeing in spatial proteomics maps
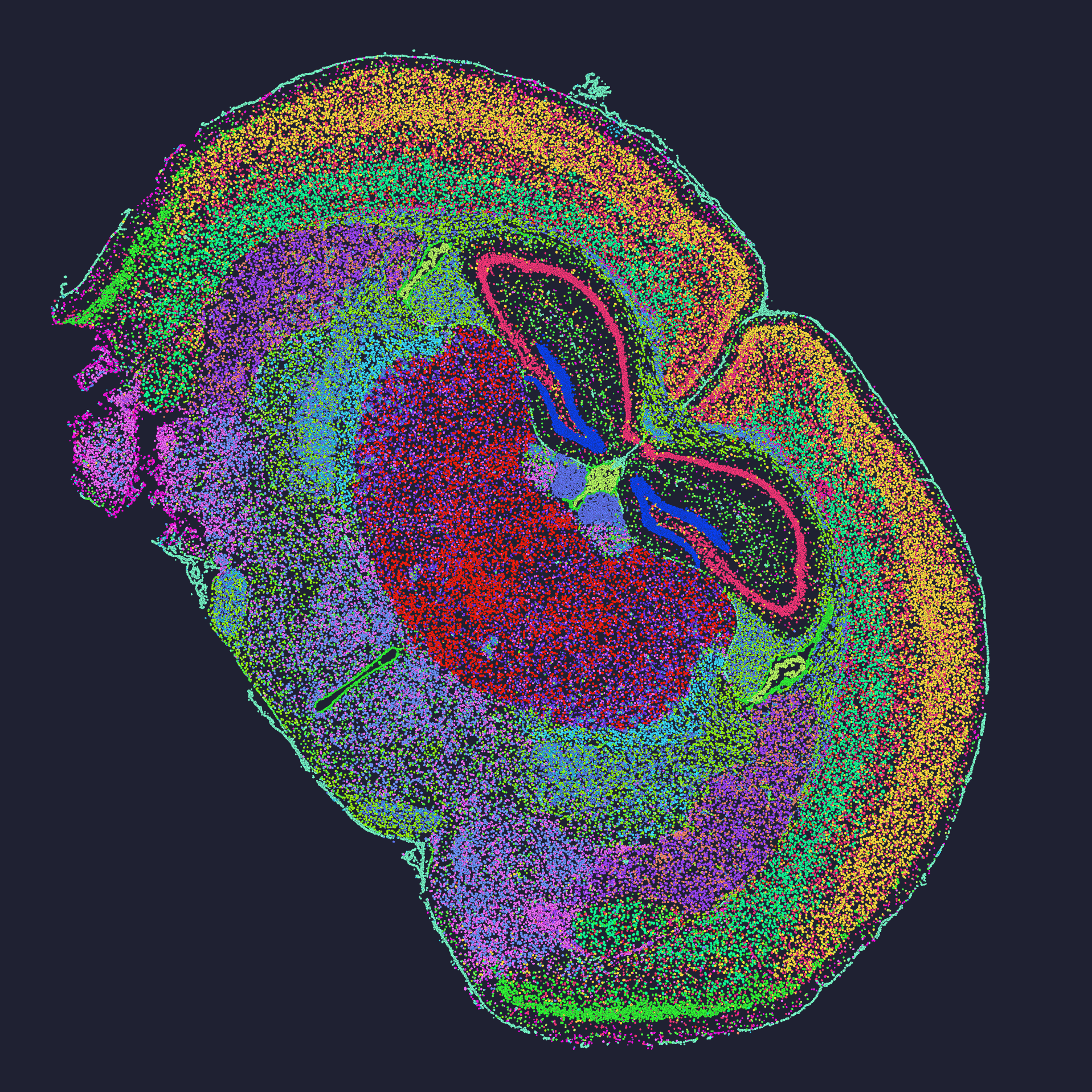
I remember the day a tumor map contradicted three years of immunohistochemistry work; I had just finished a 48-hour run using a commercial panel and the result looked pristine on-screen. spatial omics transcriptomics sits beside proteomics in the same sentence now, but they answer different questions and often produce competing views. After processing a formalin-fixed sample (scenario) and detecting 4,200 distinct protein-localization events across a 10 mm2 section (data), how should a team decide which signals are real and which are artifacts? (yes, I ask this in meetings).

I say this from over 15 years working with clinical labs and research groups: I ran a Stereo-seq assay on a mouse hippocampus slice in March 2023 at my Boston bench and saw how antibody cross-reactivity and inconsistent antibody conjugation can create false spatial patterns. The flaws are repeatable—poor antibody validation, variable spatial resolution, and slide-to-slide batch effects. I’ve watched a high-throughput run lose 12% of its usable spots because of tissue folding during staining; that number cost us weeks. I keep the problem-driven frame because the main issue is practical: teams adopt new workflows (often for throughput) without testing the parts that most affect biological truth—antibody specificity, control probes, and imaging alignment. We need to be honest: traditional workflows assume uniform antibody behavior and stable signal intensity. They don’t account for regional tissue accessibility or local protease activity. I’ll outline concrete fixes next, and point out where technology—good and bad—fits in.
Moving forward: metrics and comparisons that actually matter
What’s Next?
Let me define a working metric set before we compare options: sensitivity (limit of detection per protein), spatial resolution (effective microns per spot), and reproducibility (variance across technical replicates). Those three drive my procurement and protocol decisions. When I compare platforms—standard multiplex IF, CODEX-like panels, and emerging spatial proteomics suites—I first run a 6-antibody core panel on an archived FFPE block from our pathology collection (June 2022 batch). That small test reveals whether antibody conjugation chemistry and imaging pipeline preserve true spatial gradients. I prefer semi-quantitative readouts and a small set of well-characterized controls rather than a long list of convenience markers. In practice, I ask vendors for raw TIFFs, not just processed heatmaps—raw data shows me bleed-through, autofluorescence, and background patterning. Compare signal-to-noise ratios side-by-side; ask for repeat runs on adjacent sections; measure spot loss after registration. Note — it’s mundane but decisive.
I recommend three evaluation metrics you can use immediately: 1) percent spot retention after registration and QC (aim for >88% in routine runs), 2) coefficient of variation across three technical replicates (target <20% for core markers), and 3) confirmed co-localization with an orthogonal assay (I use single-plex IHC on a serial section for at least two markers). These metrics filter vendors and workflows more reliably than marketing slides. For labs that want to scale, consider both consumable cost per mm2 and the time-to-validated-result; a faster pipeline that doubles rework isn’t faster overall. I’ve seen turnaround time drop from 14 days to 8—once we fixed antibody lots and automated QC checks—but we only realized that after tracking the metrics above. Keep testing, keep short feedback loops. For practical choices and a suite I’ve audited in person, see stomics.