
Introduction: The Cost Curve of Neglect
I’ll start bluntly: the failure mode for big batteries is not dramatic; it’s silent drift that turns into real money. In 2022, during a 108°F week outside Pecos, I audited a 100 MW site running hithium energy storage blocks. We measured a 6.7% drop in delivered MWh versus schedule and a 14-hour spike in alarms tied to HVAC cycling—death by a thousand cuts. With a fleet like hithium bess, the data tells you what a wrench cannot. Event logs, round-trip efficiency, cell delta, and PCS ramp rates all build a simple chart: if you “set and forget,” the curve tilts down. I’ve seen that curve repeat in Pinal County, in Bakersfield, and at two coastal microgrids—each time with the same root cause. Maintenance debt accumulates while KPIs hide it in averages (and those averages lie).
So here’s my question to every asset owner and EPC I meet: are you tracking detection time and recovery time with the same rigor as capacity? If not, you’re betting the P&L on luck. Let’s get precise and compare the old playbook to what actually works—then choose with eyes open.
Why Traditional Playbooks Break on Battery Systems
What fails first — and why?
I’ve spent over 17 years in utility-scale storage and grid integration, and I’ve made the mistakes I now warn about. The gen-set mindset is the first trap. Crews apply quarterly PM checklists, tighten lugs, and call it done. On a BESS, that cycle misses the fast stuff. State-of-charge drift can creep 2–3% in a week if balancing rules are off. A power conversion system will throw ramp-limit events long before a hard fault. You won’t see it with a flashlight; you see it in 5‑minute telemetry. In Yuma during July 2021, a 40 MW/160 MWh block lost 3.2% round‑trip efficiency in 10 days because HVAC setpoints were flat and doors were opened on peak heat—an easy miss, but it shaved margin off every discharge. I prefer solutions that tilt toward condition-based tasks tied to BMS counters and PCS event codes, not the calendar.
Classic SCADA also hurts. I walked a site near Bakersfield in August 2023 where edge computing nodes had default timeouts. Result: stale data on string-level resistance, no alarms, and a 12-hour delay in flagging a DC insulation trend. That delay cost a derate and an RTO penalty. Firmware is another sore spot. When patching drifts, a converter and a BMS land on mismatched protocol builds. Then reactive power controls misbehave, and feeders see total harmonic distortion above 5%—and yes, in January. One more hidden sting sits in HVAC logic. Cycling builds condensation inside container corners; two months later you’re chasing false ground faults. This is where owners tell me the system is “temperamental”—and I’ve seen budgets cave in on that line item.
Comparative Outlook: New Control Principles That Stick
What’s Next
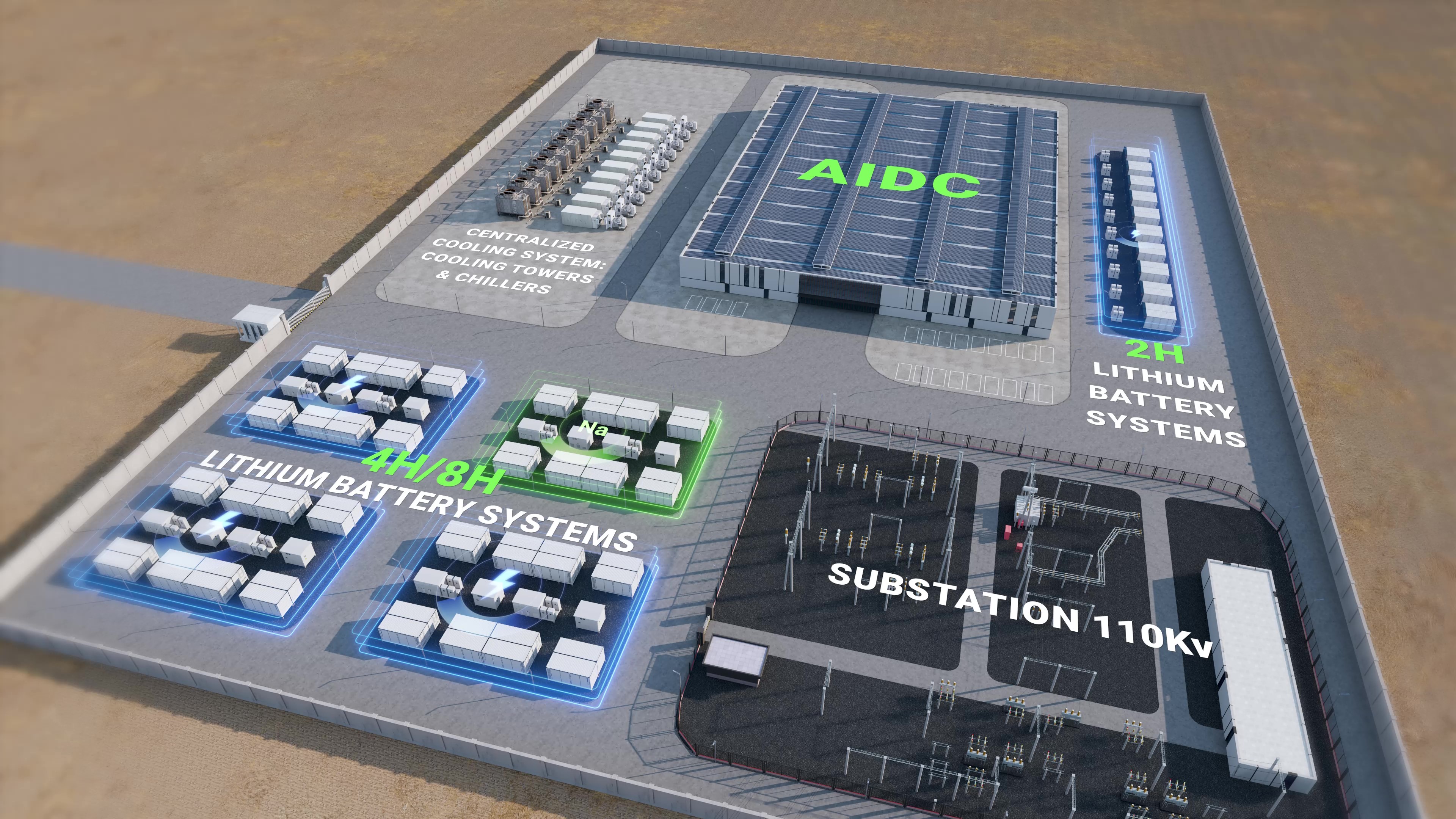
Here’s the shift that works in practice. Instead of calendar PM, anchor operations on new control principles: model‑predictive thermal control, adaptive balancing windows, and alarm budgets tied to mean time to detect. With a platform like hithium bess, you align BMS counters, PCS setpoints, and HVAC logic to a single goal: keep cell delta under 2 mV at rest and hold container dew point below 10°C over ambient. That sounds technical because it is—but it’s also simple to measure. I’ve watched a 50 MW/200 MWh site in El Paso move to predictive cooling and cut compressor run-time by 18%, while raising delivered MWh by 2.4% over 60 days. The principle is clear: use the data you already collect to change the next hour, not just document the last week. I prefer fleets that treat firmware like operations, not IT—staged rollouts, rollback in minutes, and checksum alerts pushed to a phone, not buried in a report.

Pulling the threads together, we learned the old playbook misses time-sensitive drift, firmware gaps create silent failure modes, and thermal control is not “set and forget”—it is the backbone. If you’re choosing a system or tuning one you already own, judge it on three hard metrics: first, mean time to detect (target under 5 minutes for critical BMS/PCS events); second, round‑trip efficiency stability under heat load (no more than 0.5% drop from 25°C to 40°C); third, firmware change failure rate (below 1% with auto‑rollback baked in). That’s how you keep schedules, warranties, and revenue aligned—without heroics. I carry those rules from Texas to California because they hold up under audits and storms alike. If you need a name on the gear tag for your notes, fine: HiTHIUM.